BigDL Privacy Preserving Machine Learning (PPML)¶
1. Introduction¶
Protecting privacy and confidentiality is critical for large-scale data analysis and machine learning. BigDL PPML combines various low-level hardware and software security technologies (e.g., Intel® Software Guard Extensions (Intel® SGX), Library Operating System (LibOS) such as Graphene and Occlum, Federated Learning, etc.), so that users can continue to apply standard Big Data and AI technologies (such as Apache Spark, Apache Flink, Tensorflow, PyTorch, etc.) without sacrificing privacy.
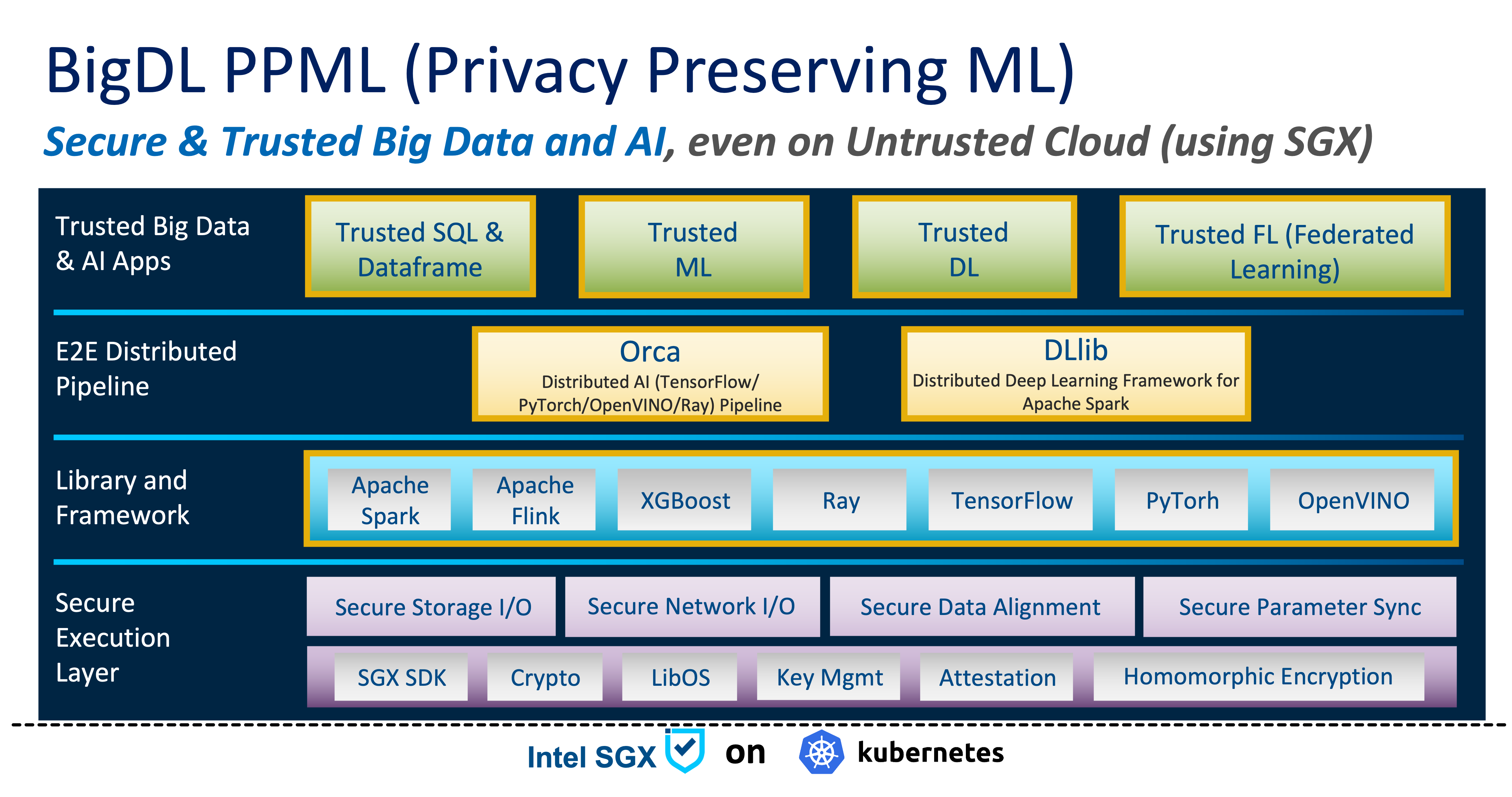 bigdl-ppml-arch
bigdl-ppml-arch
1.1 PPML for Big Data AI¶
BigDL provides a distributed PPML platform for protecting the end-to-end Big Data AI pipeline (from data ingestion, data analysis, all the way to machine learning and deep learning). In particular, it extends the single-node Trusted Execution Environment to provide a Trusted Cluster Environment, so as to run unmodified Big Data analysis and ML/DL programs in a secure fashion on (private or public) cloud:
Compute and memory protected by SGX Enclaves
Network communication protected by remote attestation and Transport Layer Security (TLS)
Storage (e.g., data and model) protected by encryption
Optional Federated Learning support
That is, even when the program runs in an untrusted cloud environment, all the data and models are protected (e.g., using encryption) on disk and network, and the compute and memory are also protected using SGX Enclaves, so as to preserve confidentiality and privacy during data analysis and machine learning.
In the current release, two types of trusted Big Data AI applications are supported:
Big Data analytics and ML/DL (supporting Apache Spark and BigDL)
Realtime compute and ML/DL (supporting Apache Flink and BigDL Cluster Serving)
2. Trusted Big Data Analytics and ML¶
With the trusted Big Data analytics and Machine Learning(ML)/Deep Learning(DL) support, users can run standard Spark data analysis (such as Spark SQL, Dataframe, Spark MLlib, etc.) and distributed deep learning (using BigDL) in a secure and trusted fashion.
2.1 Prerequisite¶
Download scripts and dockerfiles from here. And do the following commands:
cd BigDL/ppml/
Install SGX Driver
Please check if the current processor supports SGX from here. Then, enable SGX feature in BIOS. Note that after SGX is enabled, a portion of memory will be assigned to SGX (this memory cannot be seen/used by OS and other applications).
Check SGX driver with
ls /dev | grep sgx. If SGX driver is not installed, please install SGX Data Center Attestation Primitives driver from here:cd scripts/ ./install-graphene-driver.sh cd ..
Generate the signing key for SGX Enclaves
Generate the enclave key using the command below, keep it safely for future remote attestations and to start SGX Enclaves more securely. It will generate a file
enclave-key.pemin the current working directory, which will be the enclave key. To store the key elsewhere, modify the output file path.cd scripts/ openssl genrsa -3 -out enclave-key.pem 3072 cd ..
Prepare keys for TLS with root permission (test only, need input security password for keys). Please also install JDK/OpenJDK and set the environment path of the java path to get
keytool.cd scripts/ ./generate-keys.sh cd ..
When entering the passphrase or password, you could input the same password by yourself; and these passwords could also be used for the next step of generating other passwords. Password should be longer than 6 bits and contain numbers and letters, and one sample password is “3456abcd”. These passwords would be used for future remote attestations and to start SGX enclaves more securely. And This script will generate 6 files in
./ppml/scripts/keysdir (you can replace them with your own TLS keys).keystore.jks keystore.pkcs12 server.crt server.csr server.key server.pem
Generate
passwordto avoid plain text security password (used for key generation ingenerate-keys.sh) transfer.cd scripts/ ./generate-password.sh used_password_when_generate_keys cd ..
This script will generate 2 files in
./ppml/scripts/passworddir.key.txt output.bin
2.2 Trusted Big Data Analytics and ML on JVM¶
2.2.1 Prepare Docker Image¶
Pull Docker image from Dockerhub
docker pull intelanalytics/bigdl-ppml-trusted-big-data-ml-scala-graphene:2.1.0-SNAPSHOT
Alternatively, you can build Docker image from Dockerfile (this will take some time):
cd trusted-big-data-ml/python/docker-graphene
./build-docker-image.sh
2.2.2 Run Trusted Big Data and ML on Single Node¶
2.2.2.1 Start PPML Container¶
Enter BigDL/ppml/trusted-big-data-ml/python/docker-graphene dir.
Copy
keysandpasswordcd trusted-big-data-ml/python/docker-graphene # copy keys and password into the current directory cp -r ../.././../scripts/keys/ . cp -r ../.././../scripts/password/ .
Prepare the data To train a model with PPML in BigDL, you need to prepare the data first. The Docker image is taking lenet and mnist as examples.
You can download the MNIST Data from here. Unzip all the files and put them in one folder(e.g. mnist).
There are four files. train-images-idx3-ubyte contains train images, train-labels-idx1-ubyte is train label file, t10k-images-idx3-ubyte has validation images and t10k-labels-idx1-ubyte contains validation labels. For more detail, please refer to the download page.
After you decompress the gzip files, these files may be renamed by some decompress tools, e.g. train-images-idx3-ubyte is renamed to train-images.idx3-ubyte. Please change the name back before you run the example.To start the container, modify the paths in deploy-local-spark-sgx.sh, and then run the following commands:
./deploy-local-spark-sgx.sh sudo docker exec -it spark-local bash cd /ppml/trusted-big-data-ml ./init.sh
ENCLAVE_KEY_PATH means the absolute path to the “enclave-key.pem”, according to the above commands, the path would be like “BigDL/ppml/scripts/enclave-key.pem”.
DATA_PATH means the absolute path to the data(like mnist) that would use later in the spark program. According to the above commands, the path would be like “BigDL/ppml/trusted-big-data-ml/python/docker-graphene/mnist”
KEYS_PATH means the absolute path to the keys you just created and copied to. According to the above commands, the path would be like “BigDL/ppml/trusted-big-data-ml/python/docker-graphene/keys”
LOCAL_IP means your local IP address.
2.2.2.2 Run Your Spark Program with BigDL PPML on SGX¶
To run your pyspark program, you need to prepare your own pyspark program and put it under the trusted directory in SGX /ppml/trusted-big-data-ml/work. Then run with ppml-spark-submit.sh using the command:
./ppml-spark-submit.sh work/YOUR_PROMGRAM.py | tee YOUR_PROGRAM-sgx.log
When the program finishes, check the results with the log YOUR_PROGRAM-sgx.log.
2.2.2.3 Run Trusted Spark Examples with BigDL PPML SGX¶
2.2.2.3.1 Run Trusted Spark Pi¶
This example runs a simple Spark PI program, which is an easy way to verify if the Trusted PPML environment is ready.
Run the script to run trusted Spark Pi:
bash start-spark-local-pi-sgx.sh
Open another terminal and check the log:
sudo docker exec -it spark-local cat /ppml/trusted-big-data-ml/spark.local.pi.sgx.log | egrep "###|INFO|Pi"
The result should look something like this:
Pi is roughly 3.1422957114785572
2.2.2.3.2 Run Trusted Spark SQL¶
This example shows how to run trusted Spark SQL (e.g., TPC-H queries).
First, download and install sbt from here and deploy an Hadoop Distributed File System(HDFS) from here for the Transaction Processing Performance Council Benchmark H (TPC-H) dataset and output, then build the source codes with SBT and generate the TPC-H dataset according to the TPC-H example from here. After that, check if there is spark-tpc-h-queries_2.11-1.0.jar under tpch-spark/target/scala-2.11; if so, we have successfully packaged the project.
Copy the TPC-H package to the container:
docker cp tpch-spark/ spark-local:/ppml/trusted-big-data-ml/work
docker cp tpch-spark/start-spark-local-tpc-h-sgx.sh spark-local:/ppml/trusted-big-data-ml/
sudo docker exec -it spark-local bash
cd /ppml/trusted-big-data-ml/
Then run the script below:
bash start-spark-local-tpc-h-sgx.sh [your_hdfs_tpch_data_dir] [your_hdfs_output_dir]
Open another terminal and check the log:
sudo docker exec -it spark-local cat /ppml/trusted-big-data-ml/spark.local.tpc.h.sgx.log | egrep "###|INFO|finished"
The result should look like this:
—————-22 finished——————–
2.2.2.3.3 Run Trusted Deep Learning¶
This example shows how to run trusted deep learning (using a BigDL LetNet program).
First, download the MNIST Data from here. Use gzip -d to unzip all the downloaded files (train-images-idx3-ubyte.gz, train-labels-idx1-ubyte.gz, t10k-images-idx3-ubyte.gz, t10k-labels-idx1-ubyte.gz) and put them into folder /ppml/trusted-big-data-ml/work/data.
Then run the following script:
bash start-spark-local-train-sgx.sh
Open another terminal and check the log:
sudo docker exec -it spark-local cat /ppml/trusted-big-data-ml/spark.local.sgx.log | egrep "###|INFO"
or
sudo docker logs spark-local | egrep "###|INFO"
The result should look like this:
############# train optimized[P1182:T2:java] ---- end time: 310534 ms return from shim_write(...) = 0x1d
############# ModuleLoader.saveToFile File.saveBytes end, used 827002 ms[P1182:T2:java] ---- end time: 1142754 ms return from shim_write(...) = 0x48
############# ModuleLoader.saveToFile saveWeightsToFile end, used 842543 ms[P1182:T2:java] ---- end time: 1985297 ms return from shim_write(...) = 0x4b
############# model saved[P1182:T2:java] ---- end time: 1985297 ms return from shim_write(...) = 0x19
2.2.3 Run Trusted Big Data and ML on Cluster¶
WARNING: If you want spark standalone mode, please refer to standalone/README.md. But it is not recommended.
Follow the guide below to run Spark on Kubernetes manually. Alternatively, you can also use Helm to set everything up automatically. See kubernetes/README.md.
2.2.3.1 Configure the Environment¶
Enter
BigDL/ppml/trusted-big-data-ml/python/docker-graphenedir. Refer to the previous section about preparing data, key and password. Then run the following commands to generate your enclave key and add it to your Kubernetes cluster as a secret.
kubectl apply -f keys/keys.yaml
kubectl apply -f password/password.yaml
cd kubernetes
bash enclave-key-to-secret.sh
Create the RBAC(Role-based access control) :
kubectl create serviceaccount spark
kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=default:spark --namespace=default
Generate k8s config file, modify
YOUR_DIRto the location you want to store the config:
kubectl config view --flatten --minify > /YOUR_DIR/kubeconfig
Create k8s secret, the secret created
YOUR_SECRETshould be the same as the password you specified in step 1:
kubectl create secret generic spark-secret --from-literal secret=YOUR_SECRET
2.2.3.2 Start the client container¶
Configure the environment variables in the following script before running it. Check Bigdl ppml SGX related configurations for detailed memory configurations. Modify YOUR_DIR to the location you specify in section 2.2.3.1. Modify $LOCAL_IP to the IP address of your machine.
export K8S_MASTER=k8s://$( sudo kubectl cluster-info | grep 'https.*' -o -m 1 )
echo The k8s master is $K8S_MASTER .
export ENCLAVE_KEY=/YOUR_DIR/enclave-key.pem
export DATA_PATH=/YOUR_DIR/data
export KEYS_PATH=/YOUR_DIR/keys
export SECURE_PASSWORD_PATH=/YOUR_DIR/password
export KUBECONFIG_PATH=/YOUR_DIR/kubeconfig
export LOCAL_IP=$LOCAL_IP
export DOCKER_IMAGE=intelanalytics/bigdl-ppml-trusted-big-data-ml-python-graphene:2.1.0-SNAPSHOT
sudo docker run -itd \
--privileged \
--net=host \
--name=spark-local-k8s-client \
--cpuset-cpus="0-4" \
--oom-kill-disable \
--device=/dev/sgx/enclave \
--device=/dev/sgx/provision \
-v /var/run/aesmd/aesm.socket:/var/run/aesmd/aesm.socket \
-v $ENCLAVE_KEY:/graphene/Pal/src/host/Linux-SGX/signer/enclave-key.pem \
-v $DATA_PATH:/ppml/trusted-big-data-ml/work/data \
-v $KEYS_PATH:/ppml/trusted-big-data-ml/work/keys \
-v $SECURE_PASSWORD_PATH:/ppml/trusted-big-data-ml/work/password \
-v $KUBECONFIG_PATH:/root/.kube/config \
-e RUNTIME_SPARK_MASTER=$K8S_MASTER \
-e RUNTIME_K8S_SERVICE_ACCOUNT=spark \
-e RUNTIME_K8S_SPARK_IMAGE=$DOCKER_IMAGE \
-e RUNTIME_DRIVER_HOST=$LOCAL_IP \
-e RUNTIME_DRIVER_PORT=54321 \
-e RUNTIME_DRIVER_CORES=1 \
-e RUNTIME_EXECUTOR_INSTANCES=1 \
-e RUNTIME_EXECUTOR_CORES=8 \
-e RUNTIME_EXECUTOR_MEMORY=1g \
-e RUNTIME_TOTAL_EXECUTOR_CORES=4 \
-e RUNTIME_DRIVER_CORES=4 \
-e RUNTIME_DRIVER_MEMORY=1g \
-e SGX_DRIVER_MEM=32g \
-e SGX_DRIVER_JVM_MEM=8g \
-e SGX_EXECUTOR_MEM=32g \
-e SGX_EXECUTOR_JVM_MEM=12g \
-e SGX_ENABLED=true \
-e SGX_LOG_LEVEL=error \
-e SPARK_MODE=client \
-e LOCAL_IP=$LOCAL_IP \
$DOCKER_IMAGE bash
2.2.3.3 Init the client and run Spark applications on k8s¶
Run
docker exec -it spark-local-k8s-client bashto entry the container. Then run the following command to init the Spark local k8s client.
./init.sh
We assume you have a working Network File System (NFS) configured for your Kubernetes cluster. Configure the
nfsvolumeclaimon the last line to the name of the Persistent Volume Claim (PVC) of your NFS.Please prepare the following and put them in your NFS directory:
The data (in a directory called
data)The kubeconfig file.
Run the following command to start Spark-Pi example. When the appliction runs in
clustermode, you can runkubectl get podto get the name and status of your k8s pod(e.g. driver-xxxx). Then you can runkubectl logs -f driver-xxxxto get the output of your appliction.
#!/bin/bash
secure_password=`openssl rsautl -inkey /ppml/trusted-big-data-ml/work/password/key.txt -decrypt </ppml/trusted-big-data-ml/work/password/output.bin` && \
export TF_MKL_ALLOC_MAX_BYTES=10737418240 && \
export SPARK_LOCAL_IP=$LOCAL_IP && \
/opt/jdk8/bin/java \
-cp '/ppml/trusted-big-data-ml/work/spark-3.1.2/conf/:/ppml/trusted-big-data-ml/work/spark-3.1.2/jars/*' \
-Xmx8g \
org.apache.spark.deploy.SparkSubmit \
--master $RUNTIME_SPARK_MASTER \
--deploy-mode $SPARK_MODE \
--name spark-pi-sgx \
--conf spark.driver.host=$SPARK_LOCAL_IP \
--conf spark.driver.port=$RUNTIME_DRIVER_PORT \
--conf spark.driver.memory=$RUNTIME_DRIVER_MEMORY \
--conf spark.driver.cores=$RUNTIME_DRIVER_CORES \
--conf spark.executor.cores=$RUNTIME_EXECUTOR_CORES \
--conf spark.executor.memory=$RUNTIME_EXECUTOR_MEMORY \
--conf spark.executor.instances=$RUNTIME_EXECUTOR_INSTANCES \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \
--conf spark.kubernetes.container.image=$RUNTIME_K8S_SPARK_IMAGE \
--conf spark.kubernetes.driver.podTemplateFile=/ppml/trusted-big-data-ml/spark-driver-template.yaml \
--conf spark.kubernetes.executor.podTemplateFile=/ppml/trusted-big-data-ml/spark-executor-template.yaml \
--conf spark.kubernetes.executor.deleteOnTermination=false \
--conf spark.network.timeout=10000000 \
--conf spark.executor.heartbeatInterval=10000000 \
--conf spark.python.use.daemon=false \
--conf spark.python.worker.reuse=false \
--conf spark.kubernetes.sgx.enabled=$SGX_ENABLED \
--conf spark.kubernetes.sgx.driver.mem=$SGX_DRIVER_MEM \
--conf spark.kubernetes.sgx.driver.jvm.mem=$SGX_DRIVER_JVM_MEM \
--conf spark.kubernetes.sgx.executor.mem=$SGX_EXECUTOR_MEM \
--conf spark.kubernetes.sgx.executor.jvm.mem=$SGX_EXECUTOR_JVM_MEM \
--conf spark.kubernetes.sgx.log.level=$SGX_LOG_LEVEL \
--conf spark.authenticate=true \
--conf spark.authenticate.secret=$secure_password \
--conf spark.kubernetes.executor.secretKeyRef.SPARK_AUTHENTICATE_SECRET="spark-secret:secret" \
--conf spark.kubernetes.driver.secretKeyRef.SPARK_AUTHENTICATE_SECRET="spark-secret:secret" \
--conf spark.authenticate.enableSaslEncryption=true \
--conf spark.network.crypto.enabled=true \
--conf spark.network.crypto.keyLength=128 \
--conf spark.network.crypto.keyFactoryAlgorithm=PBKDF2WithHmacSHA1 \
--conf spark.io.encryption.enabled=true \
--conf spark.io.encryption.keySizeBits=128 \
--conf spark.io.encryption.keygen.algorithm=HmacSHA1 \
--conf spark.ssl.enabled=true \
--conf spark.ssl.port=8043 \
--conf spark.ssl.keyPassword=$secure_password \
--conf spark.ssl.keyStore=/ppml/trusted-big-data-ml/work/keys/keystore.jks \
--conf spark.ssl.keyStorePassword=$secure_password \
--conf spark.ssl.keyStoreType=JKS \
--conf spark.ssl.trustStore=/ppml/trusted-big-data-ml/work/keys/keystore.jks \
--conf spark.ssl.trustStorePassword=$secure_password \
--conf spark.ssl.trustStoreType=JKS \
--class org.apache.spark.examples.SparkPi \
--verbose \
local:///ppml/trusted-big-data-ml/work/spark-3.1.2/examples/jars/spark-examples_2.12-3.1.2.jar 100 2>&1 | tee spark-pi-sgx-$SPARK_MODE.log
You can run your own Spark Appliction after changing --class and jar path.
local:///ppml/trusted-big-data-ml/work/spark-3.1.2/examples/jars/spark-examples_2.12-3.1.2.jar=>your_jar_path--class org.apache.spark.examples.SparkPi=>--class your_class_path
2.3 Trusted Big Data Analytics and ML with Python¶
2.3.1 Prepare Docker Image¶
Pull Docker image from Dockerhub
docker pull intelanalytics/bigdl-ppml-trusted-big-data-ml-python-graphene:2.1.0-SNAPSHOT
Alternatively, you can build Docker image from Dockerfile (this will take some time):
cd ppml/trusted-big-data-ml/python/docker-graphene
./build-docker-image.sh
2.3.2 Run Trusted Big Data and ML on Single Node¶
2.3.2.1 Start PPML Container¶
Enter BigDL/ppml/trusted-big-data-ml/python/docker-graphene directory.
Copy
keysandpasswordto the current directorycd ppml/trusted-big-data-ml/python/docker-graphene # copy keys and password into the current directory cp -r ../keys . cp -r ../password .
To start the container, modify the paths in deploy-local-spark-sgx.sh, and then run the following commands:
./deploy-local-spark-sgx.sh sudo docker exec -it spark-local bash cd /ppml/trusted-big-data-ml ./init.sh
2.3.2.2 Run Your Pyspark Program with BigDL PPML on SGX¶
To run your pyspark program, you need to prepare your own pyspark program and put it under the trusted directory in SGX /ppml/trusted-big-data-ml/work. Then run with ppml-spark-submit.sh using the command:
./ppml-spark-submit.sh work/YOUR_PROMGRAM.py | tee YOUR_PROGRAM-sgx.log
When the program finishes, check the results with the log YOUR_PROGRAM-sgx.log.
2.3.2.3 Run Python and Pyspark Examples with BigDL PPML on SGX¶
2.3.2.3.1 Run Trusted Python Helloworld¶
This example runs a simple native python program, which is an easy way to verify if the Trusted PPML environment is correctly set up.
Run the script to run trusted Python Helloworld:
bash work/start-scripts/start-python-helloworld-sgx.sh
Open another terminal and check the log:
sudo docker exec -it spark-local cat /ppml/trusted-big-data-ml/test-helloworld-sgx.log | egrep "Hello World"
The result should look something like this:
Hello World
2.3.2.3.2 Run Trusted Python Numpy¶
This example shows how to run trusted native python numpy.
Run the script to run trusted Python Numpy:
bash work/start-scripts/start-python-numpy-sgx.sh
Open another terminal and check the log:
sudo docker exec -it spark-local cat /ppml/trusted-big-data-ml/test-numpy-sgx.log | egrep "numpy.dot"
The result should look something like this:
numpy.dot: 0.034211914986371994 sec
2.3.2.3.3 Run Trusted Spark Pi¶
This example runs a simple Spark PI program.
Run the script to run trusted Spark Pi:
bash work/start-scripts/start-spark-local-pi-sgx.sh
Open another terminal and check the log:
sudo docker exec -it spark-local cat /ppml/trusted-big-data-ml/test-pi-sgx.log | egrep "roughly"
The result should look something like this:
Pi is roughly 3.146760
2.3.2.3.4 Run Trusted Spark Wordcount¶
This example runs a simple Spark Wordcount program.
Run the script to run trusted Spark Wordcount:
bash work/start-scripts/start-spark-local-wordcount-sgx.sh
Open another terminal and check the log:
sudo docker exec -it spark-local cat /ppml/trusted-big-data-ml/test-wordcount-sgx.log | egrep "print"
The result should look something like this:
print(“Hello: 1
print(sys.path);: 1
2.3.2.3.5 Run Trusted Spark SQL¶
This example shows how to run trusted Spark SQL.
First, make sure that the paths of resource in /ppml/trusted-big-data-ml/work/spark-2.4.6/examples/src/main/python/sql/basic.py are the same as the paths of people.json and people.txt.
Run the script to run trusted Spark SQL:
bash work/start-scripts/start-spark-local-sql-sgx.sh
Open another terminal and check the log:
sudo docker exec -it spark-local cat /ppml/trusted-big-data-ml/test-sql-basic-sgx.log | egrep "Justin"
The result should look something like this:
| 19| Justin|
| Justin|
| Justin| 20|
| 19| Justin|
| 19| Justin|
| 19| Justin|
Name: Justin
| Justin|
2.3.2.3.6 Run Trusted Spark BigDL¶
This example shows how to run trusted Spark BigDL.
Run the script to run trusted Spark BigDL and it would take some time to show the final results:
bash work/start-scripts/start-spark-local-bigdl-sgx.sh
Open another terminal and check the log:
sudo docker exec -it spark-local cat /ppml/trusted-big-data-ml/test-bigdl-lenet-sgx.log | egrep "Accuracy"
The result should look something like this:
creating: createTop1Accuracy
2021-06-18 01:39:45 INFO DistriOptimizer$:180 - [Epoch 1 60032/60000][Iteration 469][Wall Clock 457.926565s] Top1Accuracy is Accuracy(correct: 9488, count: 10000, accuracy: 0.9488)
2021-06-18 01:46:20 INFO DistriOptimizer$:180 - [Epoch 2 60032/60000][Iteration 938][Wall Clock 845.747782s] Top1Accuracy is Accuracy(correct: 9696, count: 10000, accuracy: 0.9696)
2.3.3 Run Trusted Big Data and ML on Cluster¶
2.3.3.1 Configure the Environment¶
Prerequisite: passwordless ssh login to all the nodes needs to be properly set up first.
nano environments.sh
2.3.3.2 Start Distributed Big Data and ML Platform¶
First run the following command to start the service:
./deploy-distributed-standalone-spark.sh
Then start the service:
./start-distributed-spark-driver.sh
After that, you can run previous examples on the cluster by replacing --master 'local[4]' in the start scripts with
--master 'spark://your_master_url' \
--conf spark.authenticate=true \
--conf spark.authenticate.secret=your_secret_key \
2.3.3.3 Stop Distributed Big Data and ML Platform¶
First, stop the training:
./stop-distributed-standalone-spark.sh
Then stop the service:
./undeploy-distributed-standalone-spark.sh
3. Trusted Realtime Compute and ML¶
With the Trusted Realtime Compute and ML/DL support, users can run standard Flink stream processing and distributed DL model inference (using Cluster Serving in a secure and trusted fashion. In this feature, both Graphene and Occlum are supported, users can choose one of them as LibOS layer.
3.1 Prerequisite¶
Please refer to Section 2.1 Prerequisite. For the Occlum backend, if your kernel version is below 5.11, please install enable_rdfsbase from here.
3.2 Prepare Docker Image¶
Pull Docker image from Dockerhub
# For Graphene
docker pull intelanalytics/bigdl-ppml-trusted-realtime-ml-scala-graphene:2.1.0-SNAPSHOT
# For Occlum
docker pull intelanalytics/bigdl-ppml-trusted-realtime-ml-scala-occlum:2.1.0-SNAPSHOT
Also, you can build Docker image from Dockerfile (this will take some time).
# For Graphene
cd ppml/trusted-realtime-ml/scala/docker-graphene
./build-docker-image.sh
# For Occlum
cd ppml/trusted-realtime-ml/scala/docker-occlum
./build-docker-image.sh
3.3 Run Trusted Realtime Compute and ML¶
3.3.1 Configure the Environment¶
Enter BigDL/ppml/trusted-realtime-ml/scala/docker-graphene or BigDL/ppml/trusted-realtime-ml/scala/docker-occlum dir.
Modify environments.sh. Change MASTER, WORKER IP and file paths (e.g., keys and password).
nano environments.sh
3.3.3 Run Trusted Flink Program¶
Submit Flink jobs:
cd ${FLINK_HOME}
./bin/flink run ./examples/batch/WordCount.jar
If Jobmanager is not running on the current node, please add -m ${FLINK_JOB_MANAGER_IP}.
The result should look like this:
(a,5)
(action,1)
(after,1)
(against,1)
(all,2)
(and,12)
(arms,1)
(arrows,1)
(awry,1)
(ay,1)
(bare,1)
(be,4)
(bear,3)
(bodkin,1)
(bourn,1)
3.3.4 Run Trusted Cluster Serving¶
Start Cluster Serving as follows:
./start-local-cluster-serving.sh
After all services are ready, you can directly push inference requests int queue with Restful API. Also, you can push image/input into queue with Python API
from bigdl.serving.client import InputQueue
input_api = InputQueue()
input_api.enqueue('my-image1', user_define_key={"path": 'path/to/image1'})
Cluster Serving service is a long running service in container, you can stop it as follows:
docker stop trusted-cluster-serving-local