Vertical Federated Learning¶
Background¶
With the increasing concerns on data security and user privacy in machine learning, federated learning becomes a promising solution to privacy and security challenges. Federated Learning can be classified into Vertical Federated Learning, Horizontal Federated Learning, Federated Transfer Learning (FTL) according to how sensitive data are distributed among participating parties.
Federated Learning usually adopts three major technologies in protecting privacy: Differential Privacy (DP), Homomorphic Encryption (HE) and Muti-Party Computation (MPC). The privacy protection technologies that are adopted in deep neural networks are DP and MPC and TEE (Trusted Executing Environment). This solution presents an innovative way to presents an secure enhanced Vertical Federated Learning by integrating Intel SGX technology.
Vertical Federated Learning assumes that the data are partitioned by different features (including labels). A typical scenario of Vertical Federated Learning is including two parts: online reference and offline training. When an online media platform A displays ads of an e-commerce company B to its users and charges B for each conversion (e.g., user clicking the ad and buying the product).
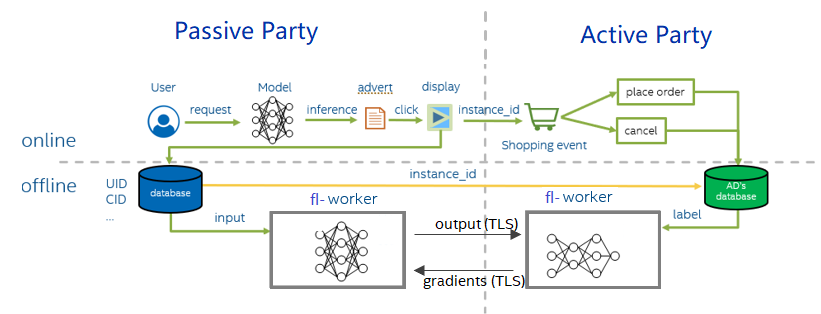 vertical FL
vertical FL
During offline training, active party and passive party , both parties use the example_id recorded online to align the data and label, and then read the data in the order of alignment. The model is divided into two parts. The passive party inputs the data into the first half, obtains the intermediate result (embedding) and then sends it to active party. Active party calculates the second half of the model, then use the label they record to calculate the loss and gradient, and then pass the gradient back to the passive party. Finally, the active party and passive party update their models.
Introduction¶
In this solution, it focuses on online training part and the main involved modules are as below:
AI Framework – Fedlearner, a Bytedance end-to-end open-source framework, based on TensorFlow, for machine learning, providing interfaces that facilitate federated learning tasks.
Security Isolation LibOS – Gramine, an open-source project for Intel SGX, run applications in an isolated environment with no modification in Intel SGX.
Containerization using Docker - The framework of this solution is built in Docker and can be automating deployment, management of containerized with Kubernetes.
Runtime Security - AI framework Fedlearner will run into Intel SGX Enclave, which offers hardware-based memory encryption that isolates specific application code and data in memory.
Model Protection - Protecting the confidentiality and integrity of the model by encryption when training takes place on an untrusted platform.
Data Protection - Establishing a secure communication link (RA-TLS enhanced gRPC) from parameter server to worker and worker to worker.
Platform Integrity - Providing Remote Attestation mechanism when workers begins to communicate with each other during the handshake. Please refer to RA-TLS enhanced gRPC for more details.
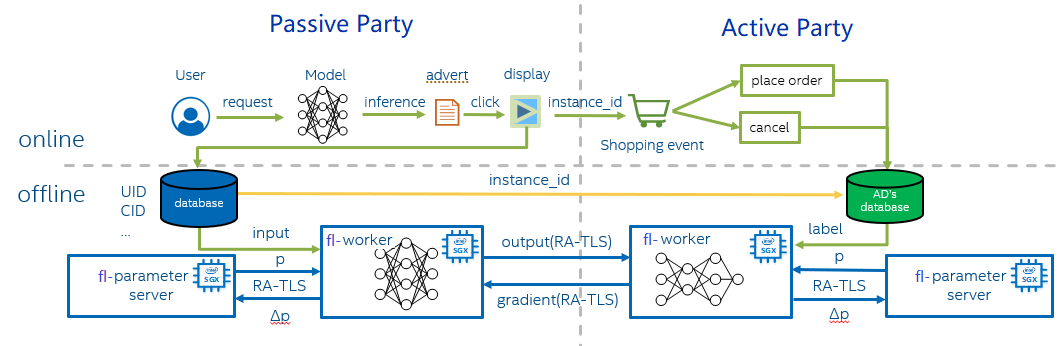 Vertical FL with SGX
Vertical FL with SGX
Usually, there are two roles during model training - parameter server and workers. Each worker computes the gradient of the loss on its portion of the data, and then a parameter server sums each worker’s gradient to yield the full mini-batch gradient. After using this gradient to update the model parameters, the parameter server must send back the updated weights to the worker. Workers from active party and passive party will transfer labels and gradients via gRPC.
Runtime security with Intel SGX
Intel SGX allows user-level code to allocate private regions of memory, called Enclaves, which are designed to be protected from processes running at higher privilege levels. It also helps protect against SW attacks even if OS/drivers/BIOS/VMM/SMM are compromised and helps increase protections for secrets even when attacker has full control of platform. In this solution, parameter server and worker are both running SGX Enclave smoothly with the help of LibOS Gramine.
Attestation and Authentication
In this solution, when two workers build the connection via gRPC, before the communication channel establish successfully, the workers will verify each other with two parts: remote attestation and identity authentication.
In remote attestation, generally the attesting SGX enclave collects attestation evidence in the form of an SGX Quote using the Quoting Enclave. This form of attestation is used to gain the remote partner’s trust by sending the attestation evidence to a remote party (not on the same physical machine).
When workers begin the communication via gRPC, the SGX Quote will be integrated in TLS and verified in the other worker side by the preinstalled Intel SGX DCAP package in the container.
Besides the verification of the Enclave, it also checks the identity information (mr_enclave,mr_signer,isv_prod_id,isv_svn) of the Enclave which excludes the possibility of authenticating them via a user identity.
Once the verification and identity check pass, the communication channel between workers will be built successfully. More details please refer to RA-TLS enhanced gRPC.
Data at-rest security
We encrypt models with cryptographic (wrap) key by using Protected-File mode in LibOS Gramine to guarantee the integrity of the model file by metadata checking method. Any changes of the model will have a different hash code, which will be denied by Gramine .
Prerequisites¶
Ubuntu 18.04. This solution should work on other Linux distributions as well, but for simplicity we provide the steps for Ubuntu 18.04 only.
Docker Engine. Docker Engine is an open source containerization technology for building and containerizing your applications. In this solution, Gramine, Fedlearner, gRPC will be built in a Docker image. Please follow this guide to install Docker Engine. The Docker daemon’s storage location (/var/lib/docker for example) should have at least 32GB available.
CCZoo Vertical Federated Learning source package:
git clone https://github.com/intel/confidential-computing-zoo.git
SGX capable platform. Intel SGX Driver and SDK/PSW. You need a machine that supports Intel SGX and FLC/DCAP. If the Intel SGX driver and SDK/PSW is already installed on your machine/VM, the following steps can be skipped. For example, the following steps are not necessary and can be skipped for Azure deployments.
Please follow this guide to install the Intel SGX driver and SDK/PSW. One way to verify SGX enabling status in your machine is to run QuoteGeneration and QuoteVerification successfully.
Executing Fedlearner in SGX¶
1. Download source code¶
Download the Fedlearner source code:
cd cczoo/vertical_fl
git clone -b fix_dev_sgx https://github.com/bytedance/fedlearner.git vertical_fl
cd vertical_fl
git checkout 75e8043
cd ..
./apply_overlay.sh
cd vertical_fl
2. Build Docker image¶
build_dev_docker_image.sh provides the parameter proxy_server to specify the network proxy. build_dev_docker_image.sh also accepts an optional argument to specify the docker image tag.
For deployments on Microsoft Azure:
AZURE=1 ./sgx/build_dev_docker_image.sh
For other cloud deployments:
./sgx/build_dev_docker_image.sh
Example of built image:
REPOSITORY TAG IMAGE ID CREATED SIZE
fedlearner-sgx-dev latest 8c3c7a05f973 45 hours ago 15.2GB
3. Start Container¶
Start the leader and follower containers:
docker run -itd --name=fedlearner_leader --restart=unless-stopped -p 50051:50051 \
--device=/dev/sgx_enclave:/dev/sgx/enclave --device=/dev/sgx_provision:/dev/sgx/provision fedlearner-sgx-dev:latest bash
docker run -itd --name=fedlearner_follower --restart=unless-stopped -p 50052:50052 \
--device=/dev/sgx_enclave:/dev/sgx/enclave --device=/dev/sgx_provision:/dev/sgx/provision fedlearner-sgx-dev:latest bash
Take note of the container IP addresses for later steps:
docker inspect --format '{{ .NetworkSettings.IPAddress }}' fedlearner_leader
docker inspect --format '{{ .NetworkSettings.IPAddress }}' fedlearner_follower
In terminal 1, enter the leader container shell:
docker exec -it fedlearner_leader bash
In terminal 2, enter the follower container shell:
docker exec -it fedlearner_follower bash
3.1 Configure PCCS¶
For deployments on Microsoft Azure, skip this section, as configuring the PCCS is not necessary on Azure.
If you are using public cloud instance, please replace the PCCS url in
/etc/sgx_default_qcnl.confwith the new pccs url provided by the cloud.Old: PCCS_URL=https://pccs.service.com:8081/sgx/certification/v3/ New: PCCS_URL=https://public_cloud_pccs_url
If you are using your own machine, please make sure, the PCCS service is running successfully in your host with command
systemctl status pccs. And add your host IP address in/etc/hostsunder container. For example:cat /etc/hosts XXX.XXX.XXX.XXX pccs.service.com #XXX.XXX.XXX.XXX is the host IP
3.2 Start aesm service¶
Start the aesm service in both the leader and follower containers:
/root/start_aesm_service.sh
Verify the aesm service is running in both the leader and follower containers:
# ps aux |grep aesm_service
root 35 0.1 0.0 293004 16788 ? Ssl 03:26 0:00 /opt/intel/sgx-aesm-service/aesm/aesm_service
root 44 0.0 0.0 13220 1068 pts/1 S+ 03:26 0:00 grep --color=auto aesm_service
4. Prepare data¶
Generate data in both the leader and follower containers:
cd /gramine/CI-Examples/wide_n_deep
./test-ps-sgx.sh data
5. Compile applications¶
Compile applications in both the leader and follower containers:
cd /gramine/CI-Examples/wide_n_deep
./test-ps-sgx.sh make
Take note of the mr_enclave and mr_signer values from the resulting log from the leader container.
The following is an example log:
+ make
+ grep 'mr_enclave\|mr_signer\|isv_prod_id\|isv_svn'
isv_prod_id: 0
isv_svn: 0
mr_enclave: bda462c6483a15f18c92bbfd0acbb61b9702344202fcc6ceed194af00a00fc02
mr_signer: dbf7a340bbed6c18345c6d202723364765d261fdb04e960deb4ca894d4274839
isv_prod_id: 0
isv_svn: 0
In both the leader and follower containers, in dynamic_config.json, confirm that mr_enclave and mr_signer are set to the values from the leader container’s log. Use the actual values from the leader container’s log, not the values from the example log above.
dynamic_config.json:
{
......
"sgx_mrs": [
{
"mr_enclave": "",
"mr_signer": "",
"isv_prod_id": "0",
"isv_svn": "0"
}
],
......
}
6. Run the distributing training¶
Start the training process in the follower container, replacing XXX.XXX.XXX.XXX with the leader container IP address. For example:
cd /gramine/CI-Examples/wide_n_deep
peer_ip=XXX.XXX.XXX.XXX
./test-ps-sgx.sh follower $peer_ip
Wait until the follower training process is ready, when the following log is displayed:
2022-10-12 02:53:47,002 [INFO]: waiting master ready... (fl_logging.py:95)
Start the training process in the leader container, replacing XXX.XXX.XXX.XXX with the follower container IP address. For example:
cd /gramine/CI-Examples/wide_n_deep
peer_ip=XXX.XXX.XXX.XXX
./test-ps-sgx.sh leader $peer_ip
The following logs occur on the leader when the leader and follower have established communication:
2022-10-12 05:22:27,056 [INFO]: [Channel] state changed from CONNECTING_UNCONNECTED to CONNECTING_CONNECTED, event: PEER_CONNECTED (fl_logging.py:95)
2022-10-12 05:22:27,067 [INFO]: [Channel] state changed from CONNECTING_CONNECTED to READY, event: CONNECTED (fl_logging.py:95)
2022-10-12 05:22:27,068 [DEBUG]: [Bridge] stream transmit started (fl_logging.py:98)
The following logs on the leader are an example of a training iteration:
2022-10-12 05:23:52,356 [DEBUG]: [Bridge] send start iter_id: 123 (fl_logging.py:98)
2022-10-12 05:23:52,483 [DEBUG]: [Bridge] receive peer commit iter_id: 122 (fl_logging.py:98)
2022-10-12 05:23:52,484 [DEBUG]: [Bridge] received peer start iter_id: 123 (fl_logging.py:98)
2022-10-12 05:23:52,736 [DEBUG]: [Bridge] received data iter_id: 123, name: act1_f (fl_logging.py:98)
2022-10-12 05:23:52,737 [DEBUG]: [Bridge] Data: received iter_id: 123, name: act1_f after 0.117231 sec (fl_logging.py:98)
2022-10-12 05:23:52,739 [DEBUG]: [Bridge] Data: send iter_id: 123, name: act1_f_grad (fl_logging.py:98)
2022-10-12 05:23:52,817 [DEBUG]: [Bridge] receive peer commit iter_id: 123 (fl_logging.py:98)
2022-10-12 05:23:52,818 [DEBUG]: [Bridge] received peer start iter_id: 124 (fl_logging.py:98)
2022-10-12 05:23:53,070 [DEBUG]: [Bridge] received data iter_id: 124, name: act1_f (fl_logging.py:98)
2022-10-12 05:23:53,168 [DEBUG]: [Bridge] send commit iter_id: 123 (fl_logging.py:98)
2022-10-12 05:23:53,170 [DEBUG]: after session run. time: 0.814208 sec (fl_logging.py:98)
When the training processes are done, the leader will display these logs:
**************export model hook**************
sess : <tensorflow.python.client.session.Session object at 0x7e8fb898>
model: <fedlearner.trainer.estimator.FLModel object at 0x8ee60f98>
export_dir: model/leader/saved_model/1665552233
inputs: {'examples': <tf.Tensor 'examples:0' shape=<unknown> dtype=string>, 'act1_f': <tf.Tensor 'act1_f:0' shape=<unknown> dtype=float32>}
outpus: {'output': <tf.Tensor 'MatMul_2:0' shape=(None, 2) dtype=float32>}
*********************************************
2022-10-12 05:24:07,675 [INFO]: export_model done (fl_logging.py:95)
2022-10-12 05:24:07,676 [INFO]: Trainer Master status transfer, from WORKER_COMPLETED to COMPLETED (fl_logging.py:95)
2022-10-12 05:24:09,017 [INFO]: master completed (fl_logging.py:95)
The updated model files are saved in these locations:
./model/leader/saved_model/<id>/saved_model.pb
./model/follower/saved_model/<id>/saved_model.pb
Cloud Deployment¶
1. Aliyun ECS¶
Aliyun ECS (Elastic Compute Service) is an IaaS (Infrastructure as a Service) level cloud computing service provided by Alibaba Cloud. It builds security-enhanced instance families g7t, c7t, r7t based on Intel® SGX technology to provide a trusted and confidential environment with a higher security level.
The configuration of the ECS instance as below:
Instance Type : g7t.
Instance Kernel: 4.19.91-24
Instance OS : Alibaba Cloud Linux 2.1903
Instance Encrypted Memory: 32G
Instance vCPU : 16
Instance SGX PCCS Server Addr: sgx-dcap-server.cn-hangzhou.aliyuncs.com
Notice: Please replace server link in sgx_default_qcnl.conf included in the dockerfile with Aliyun PCCS server address.
2. Tencent Cloud¶
Tencent Cloud Virtual Machine (CVM) provide one instance named M6ce, which supports Intel® SGX encrypted computing technology.
The configuration of the M6ce instance as below:
Instance Type : M6ce.4XLARGE128
Instance Kernel: 5.4.119-19-0009.1
Instance OS : TencentOS Server 3.1
Instance Encrypted Memory: 64G
Instance vCPU : 16
Instance SGX PCCS Server: sgx-dcap-server-tc.sh.tencent.cn
Notice: Please replace server link in sgx_default_qcnl.conf included in the dockerfile with Tencent PCCS server address.
3. ByteDance Cloud¶
ByteDance Cloud (Volcengine SGX Instances) provides the instance named ebmg2t,
which supports Intel® SGX encrypted computing technology.
The configuration of the ebmg2t instance as below:
Instance Type :
ecs.ebmg2t.32xlarge.Instance Kernel: kernel-5.15
Instance OS : ubuntu-20.04
Instance Encrypted Memory: 256G
Instance vCPU : 16
Instance SGX PCCS Server:
sgx-dcap-server.bytedance.com.
4. Microsoft Azure¶
Microsoft Azure DCsv3-series instances support Intel® SGX encrypted computing technology.
DCsv3-series instance configuration:
Instance Type : Standard_DC16s_v3
Instance Kernel: 5.15.0-1020-azure
Instance OS : Ubuntu Server 20.04 LTS - Gen2
Instance Encrypted Memory: 64G
Instance vCPU : 16